
ある銘柄に投資をしていて、ある日突然、その銘柄に関する憶測のニュースを聞き、携帯電話やパソコン、証券会社で注意喚起をしたことが何度あったことでしょう。
携帯電話で銘柄名を何度も入力したり、長いリストの中から銘柄をタップしたりして、いろいろな価格をチェックしがちです。
結局のところ、多くの時間に対して得られるものは少ないのです。
しかし、簡単にスクラップできる方法がたくさんあります。
お気に入りの株価検索サイトから簡単に株価をスクラップできる方法がたくさんあります。
この記事では、PythonライブラリとしてBeautifulsoupを使用して、ページのHTMLコードからのデータスクレイピングの開発をカバーします。
Beautifulsoupとは何か、なぜそれを使うのか?
Beautifulsoupは2004年にリリースされた画面選別用のPythonライブラリで、HTMLやXMLのソースコードを使ってWebサイトからデータを抽出するために採用されています。
scrappyやseleniumなど、より優れたWebスクレイピングライブラリもありますが、今回は非常に使いやすく、習得しやすいBeautifulsoupを使用しています。
Beautifulsoupは、Javaスクリプトのような複雑なデータの抽出には苦労しますが、小規模の簡単なデータの抽出は、これを使って簡単に行うことができます。
PythonでBeautifulSoupを操作する
BeautifulSoupをPythonで動かすには、様々な方法があり、どのようなマシンやOSで動作しているかによります。
ここでは、Windows OSとPyCharm IDEでのインストール部分を取り上げ、幅広い対象者に向けて説明します。
また、PyCharm IDEではパッケージのインストールと環境の作成が簡略化されています。
PythonとPython pipがインストールされている必要があります。
cmdを開いて入力します。
pip install beautifulsoup4 |
Pythonのライブラリが自動的にインストールされます。
インストールが完了したら、次はパーサをインストールします。
パーサーはbeautifulsoupをサポートするPythonライブラリで、HTMLやXMLのコードをパースするために必要です。
pip install lxmlpip install requests |
PyCharmでBeautifulsoupをインストールする
PyCharmでのpythonパッケージのインストールは、他のIDEに比べて比較的簡単で手間がかからないので、このまま進めていきたいと思います。
- 新規プロジェクトを作成し、そのプロジェクトにpythonファイル(拡張子は.py)を添付します。
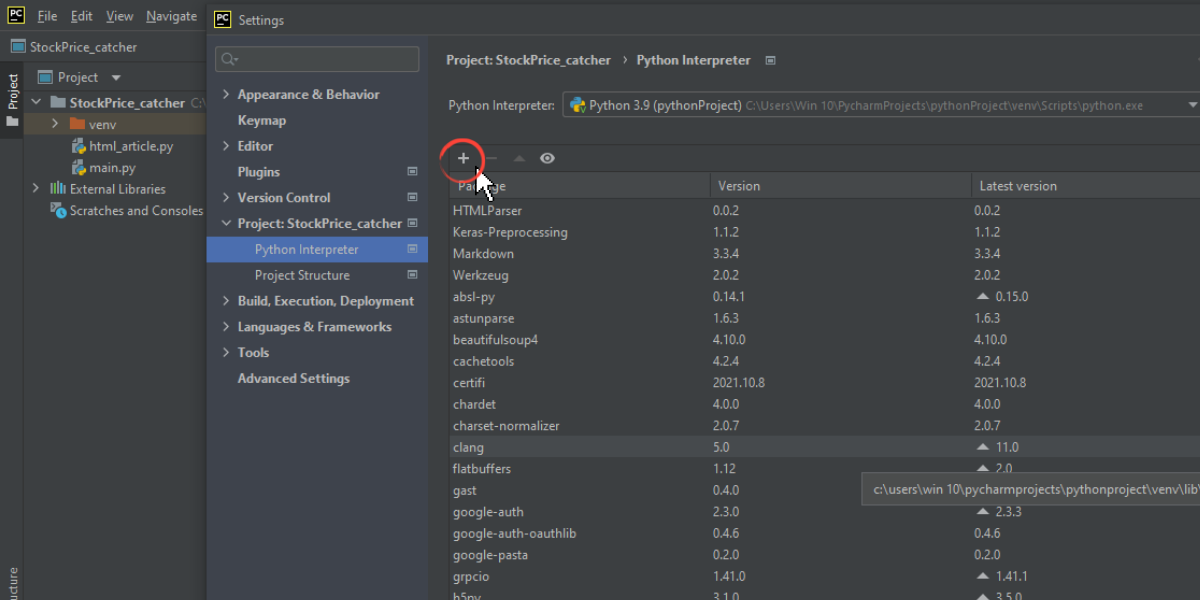
- そして、File >Settingsに向かい、左ペインで、今作成したプロジェクトのタイトルをクリックします。
- Python Interpreter」オプションは、そのプロジェクトに必要なすべてのインタープリターを含む新しいウィンドウを開きます。
- パッケージ」列の真上にあるプラス記号を探し、クリックします。
from bs4 import BeautifulSoup
import requests
url_of_page = 'https://finance.yahoo.com/quote/%5EIXIC/'
def computequoteprice():
url_requests = requests.get(url_of_page)
soup_ocreate = BeautifulSoup(url_requests.text, 'lxml')
quote_price = soup_ocreate.find('span', class_='Trsdu(0.3s) Fw(b) Fz(36px) Mb(-4px) D(ib)').text
return quote_price
print ("Quote price= " +str(computequoteprice()))
|
- それをクリックすると、Pythonインタプリタの長いリストが表示された新しいウィンドウがポップアップします。
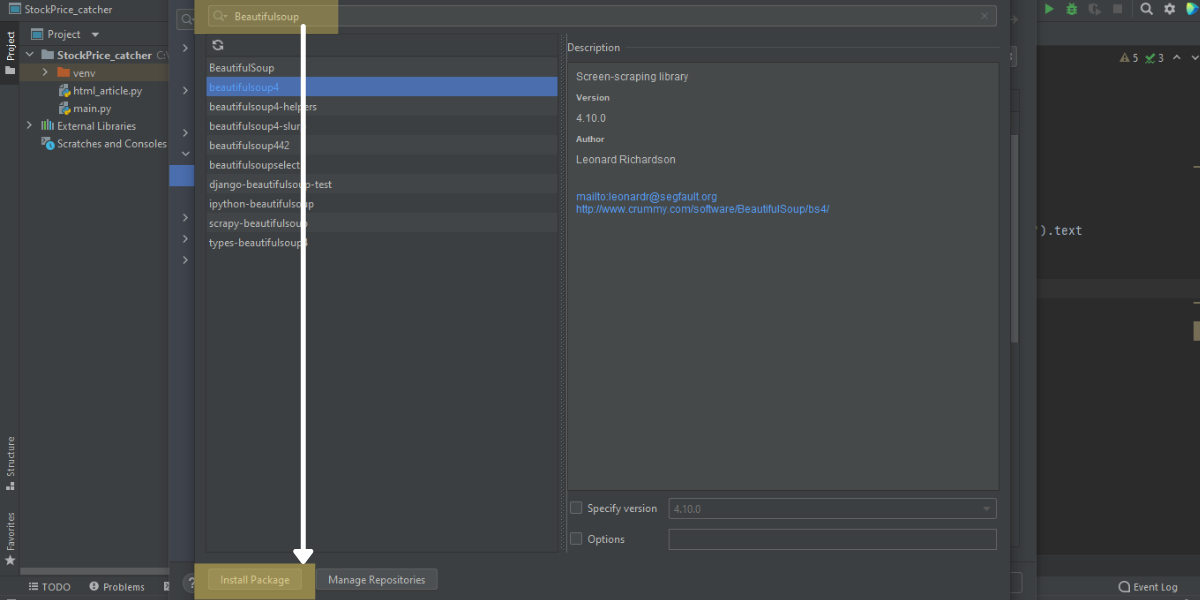
- このページでは、’Beautifulsoup4’を検索し、ページの一番下にあるInstall Packageをクリックします。
from bs4 import BeautifulSoup
import requests
url_of_page = 'https://www.moneycontrol.com/india/stockpricequote/refineries/relianceindustries/RI'
def computequoteprice():
url_requests = requests.get(url_of_page)
soup_ocreate = BeautifulSoup(url_requests.text, 'lxml')
quote_price = soup_ocreate.find('div', class_='inprice1 nsecp').text
return quote_price
print ("Quote price= " +str(computequoteprice()))
|
これでBeautifulsoup4がPyCharmにインストールされました。
HTMLから株価を取得するためには、まず以下の2つが必要です。
- ウェブサイトのURL
- 株価の属性の要素の検査
この記事では、2つの異なるWebサイトを例にして、検査する正しい属性を特定する方法を理解することにします。
ヤフーファイナンスのデータを抽出する
最初の例では、Yahoo FinanceのウェブサイトからNASDAQのリアルタイムの価格を取得することにします。
これを行うには、「Nasdaq yahoo finance」でググってください。
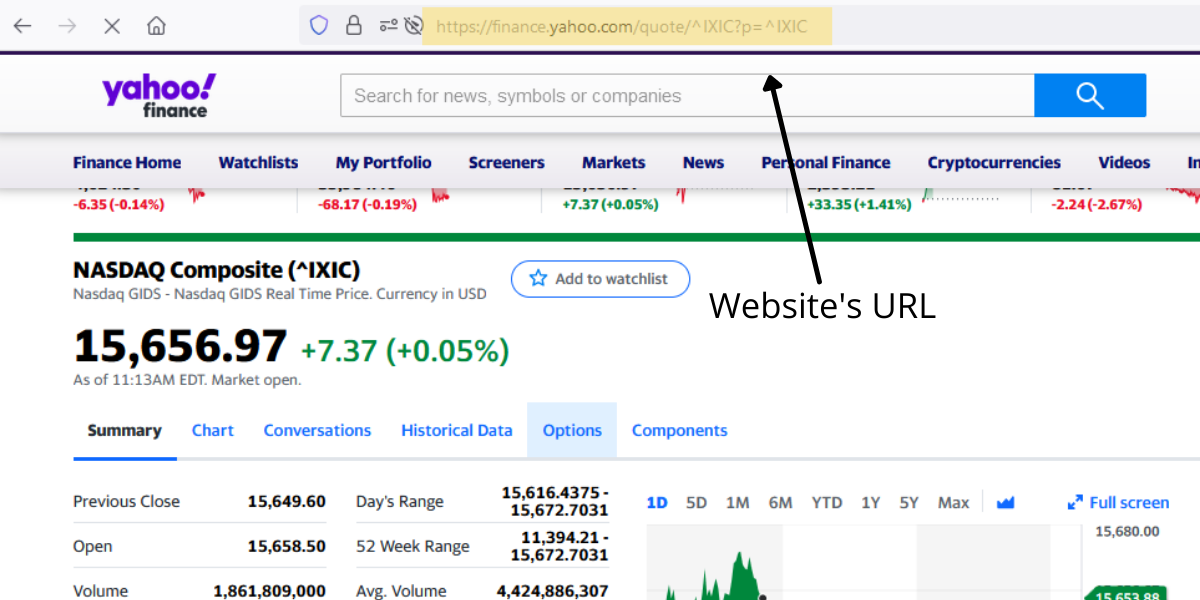
検索エンジンは、直接NASDAQの見積もり価格ページを表示します。
そこで、そのページのURLをコピーする必要があります。
次に、相場価格の属性が必要です。
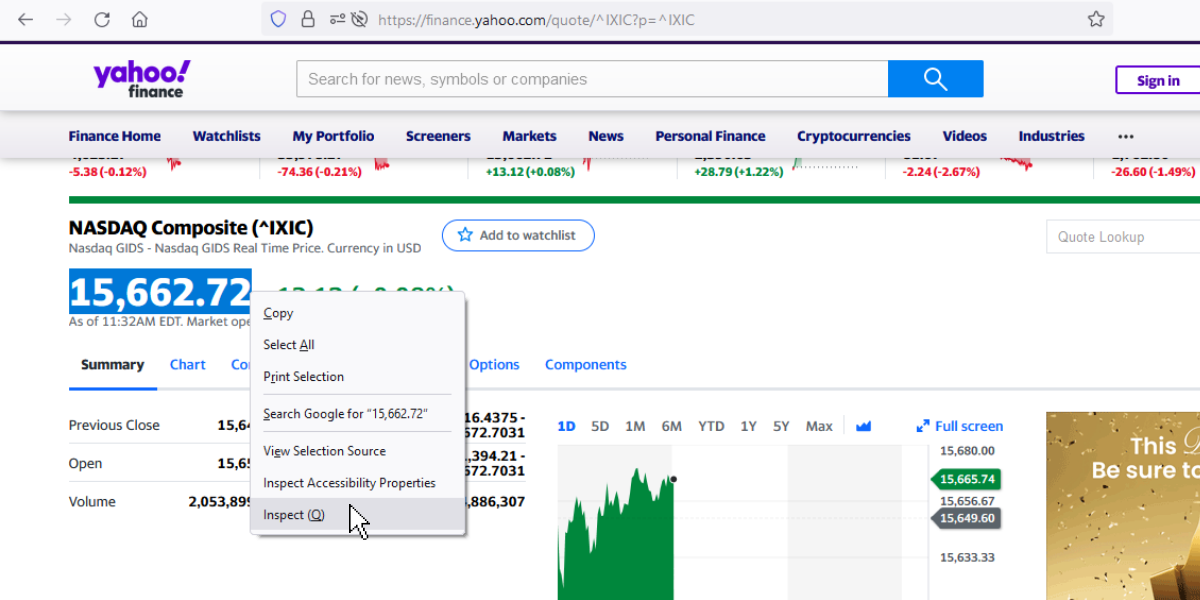
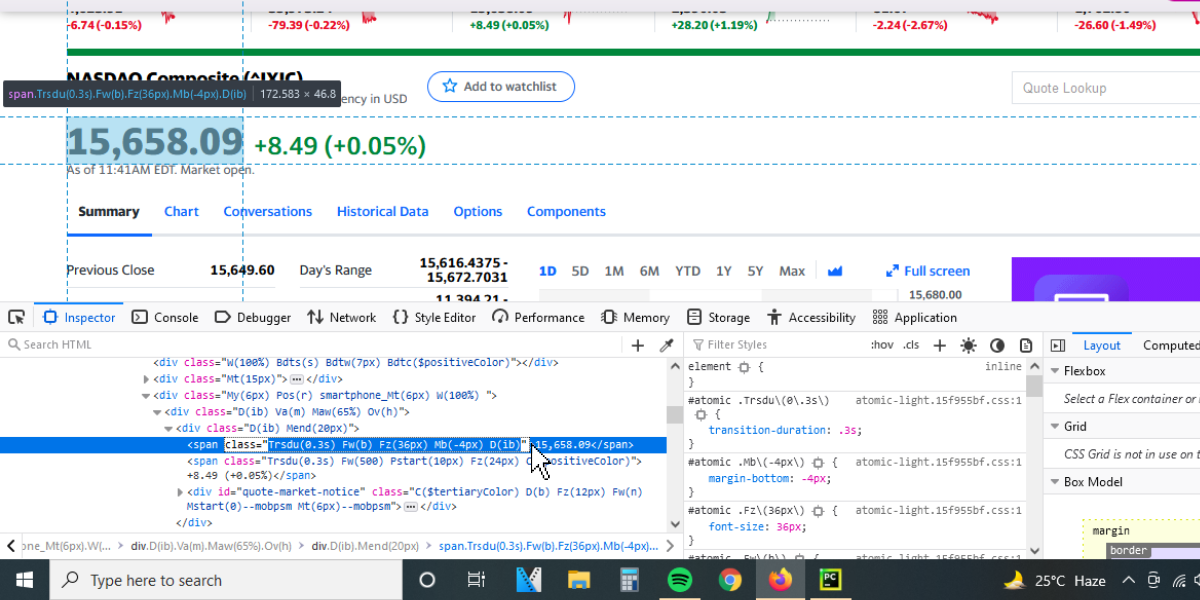
これを取得するには、気配値を選択して右クリックし、「inspect」をクリックします。
検査メニューがポップアップすると、必要な属性はすでにハイライトされています。
下の例では、必要な HTML コードがハイライトされているので、その中の必要なデータを選択してコピーするだけです。
必要なのは、二重引用符で囲まれたコードだけです。
注:埋め込まれたコードの上にカーソルを移動させると、そのコードにリンクしている要素が表示されます。
下の画像では、点線が見積もり価格を囲んでいますが、これはカーソルを埋め込まれているHTMLコードの上に置いたためです。
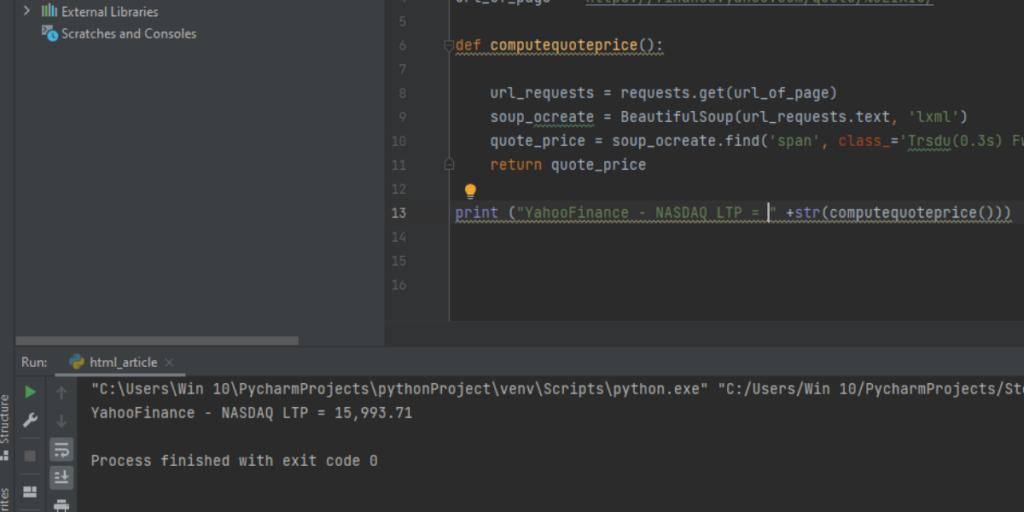
PythonによるYahoo Financeデータの抽出 BeautifulSoup
それでは、株価データを抽出するコードに入りましょう。
上記のコードでわかるように、ウェブサイトのURLは変数’url’に格納されています。
同様に、属性は変数’price’に使用されています。
このコードでは、ウェブサイトのURLにアクセスし、そのページのすべてのHTMLデータを要求します。
次に、「soup.find」コードを使用して、HTMLコード内のスパンIDを検索し、クラスには、ページから取得したい見積もり価格の属性が含まれています。
マネーコントロール
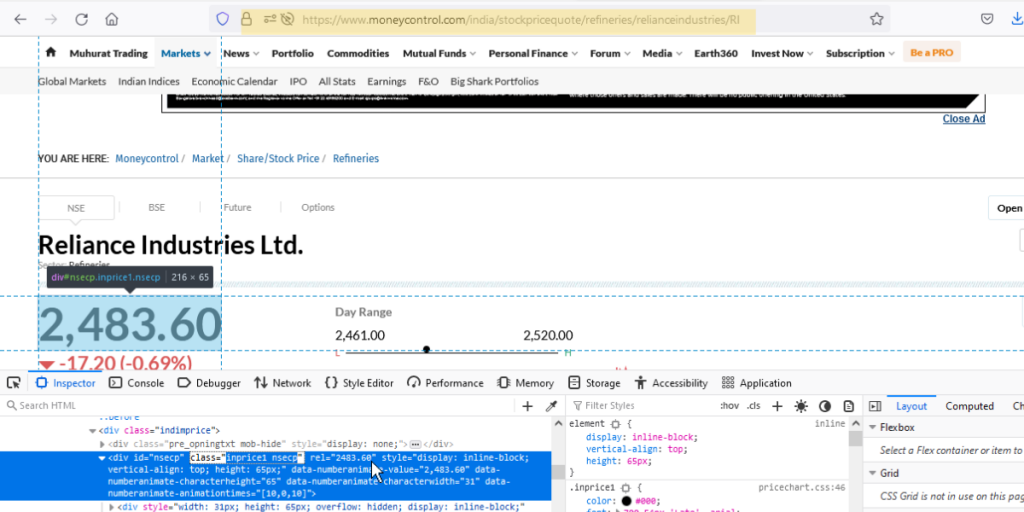
別のウェブサイトからの例を見てみましょう。
ここでは、Reliance industries の株価を moneycontrol.com から取得します。
HTMLの属性が違うだけで、手順は同じです。
Yahoo financeはidに「span」を使っているのに対し、money controlはidに「div」を使っています。
注:属性の正しいidを特定することは重要で、ウェブサイトによってidは異なりますが、全体的なプロセスは同じです。
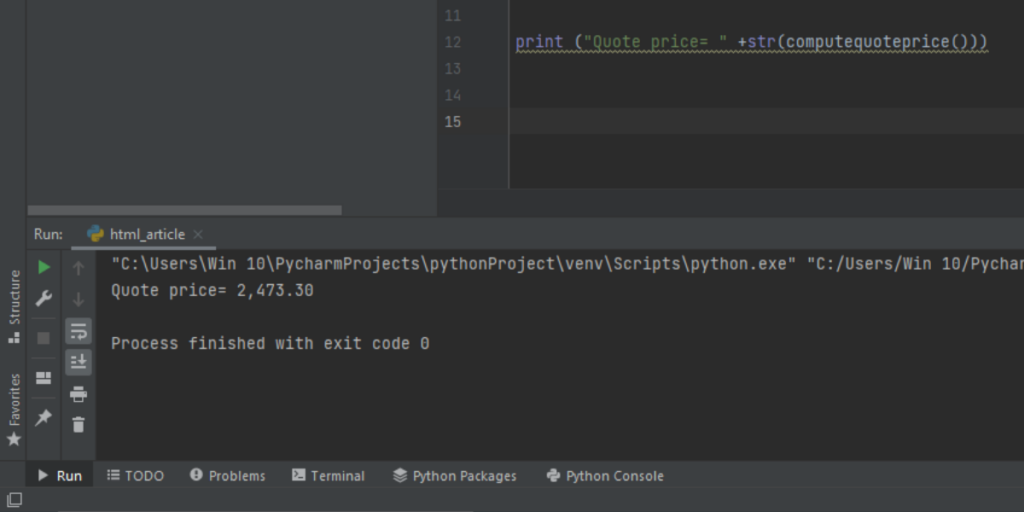
PythonでMoneycontrolから株価を抽出するコード BeautifulSoup
結論
今回は、株価スクリーニングサイトから株価を簡単に取得する方法について学びました。
また、beautifulsoupというライブラリについて、インストール方法とその動作について学びました。
株価のスクラップについてもっと知りたい方は、「Python stocks scrappy」でググってみてください。