
翌日に試験やプレゼンを控えているとき、Googleの検索ページで次々とページをめくりながら、役に立つ記事を探しているような状況に陥ったことはないでしょうか。
今回は、このような単調な作業を自動化し、より良い仕事に力を注ぐ方法をご紹介します。
この演習では、Google collaboratoryを使用し、その中でScrapyを使用することにします。
もちろん、ローカル環境に直接Scrapyをインストールしても、手順は同じです。
一括検索やAPIをお探しですか?
以下のプログラムは実験的なもので、Pythonで検索結果をスクレイピングする方法を示しています。
しかし、これを大量に実行すると、Googleファイアウォールにブロックされる可能性があります。
もし一括検索やそれに関連したサービスを作りたいのであれば、Zenserpを調べてみると良いだろう。
ZenserpはGoogleの検索APIで、検索エンジンの結果ページをスクレイピングする際の問題を解決してくれる。
検索エンジンの結果ページをスクレイピングする場合、プロキシ管理の問題にすぐに突き当たります。
Zenserpはプロキシを自動的にローテーションさせ、有効なレスポンスだけを受け取るようにします。
また、画像検索、ショッピング検索、画像逆引き検索、トレンド検索などをサポートし、作業を容易にします。
検索結果を入力して、JSONレスポンスを見ることができます。
Google Colaboratory の初期化
https://colab.research.google.com/ にアクセスし、Google アカウントでログインします。
ファイル >新しいノートブックを作成]に移動します。
そして、このアイコンに移動してクリックします。
確認ボタンをクリックします。
!pip install scrapy |
これで、数秒かかります。
そして、コード領域に、タイプします。
import scrapy
import pandas
|
これは、Google colabに組み込まれていないため、Google colab内にScrapyをインストールします。
次に、パッケージをインポートします。
%cd "/content/drive/My Drive/Colab Notebooks/"
|
ドライブをマウントしたのを覚えていますか?ドライブというフォルダに移動し、Colab Notebooksに移動します。
その上で右クリックし、Copy Pathを選択します。
次に、コードエディターで、次のように入力します。
!scrapy startproject google_crawler |
これで、scrapyプロジェクトを初期化する準備が整いました。
コードエディタに入力します。
!mv google_crawler "/content/drive/My Drive/Colab Notebooks/"
|
これで、colab notebooksの中にscrapyプロジェクトのレポが作成されます。
もし、途中でついていけなくなったり、どこかにミスがあったりして、プロジェクトが別の場所に保存されていても、心配ありません。
単に移動させればいいのです。
import scrapy
from scrapy.linkextractors import LinkExtractor
import pandas as pd
|
これが完了したら、スパイダーの構築を開始します。
Python Scrapy Spiderの構築
google_crawlerのレポを開く。
中に「spiders」フォルダがあります。
この中に新しいスパイダーコードを入れます。
このフォルダをクリックして、新しいファイルを作成し、名前を付けます。
まず、パッケージのインポートから始めます。
class firstSpider(scrapy.Spider):
name = "basic"
start_urls = [
"https://www.google.com/search?q=journal+dev"
]
|
クラス名は今のところ変更する必要はありません。
少し整理してみましょう。
allowed_domainsの行は必要ないので削除してください。
名前を変更します。
ファイルシステムはこんな感じです(参考)。
def parse(self, response):
xlink = LinkExtractor()
for link in xlink.extract_links(response):
print(link)
|
これが今回のスパイダーの名前で、いろいろなパラメータを付けて何個でも保存できます。
start_urls リストには、google 検索を追加できます。
!scrapy crawl basic |
さて、解析関数を作成して、リンク抽出器を使用してリンクを取得しましょう。
def parse(self, response):
xlink = LinkExtractor()
for link in xlink.extract_links(response):
if len(str(link))>200 or 'Journal' in link.text:
print(len(str(link)),link.text,link,")
|
コード・エディターで、この関数を実行します。
def parse(self, response):
df = pd.DataFrame()
xlink = LinkExtractor()
link_list=[]
link_text=[]
for link in xlink.extract_links(response):
if len(str(link))>200 or 'Journal' in link.text:
print(len(str(link)),link.text,link,")
link_list.append(link)
link_text.append(link.text)
df['links']=link_list
df['link_text']=link_text
df.to_csv('output.csv')
|
ここには複数のリンクがあり、その多くはほとんどGoogle.comで検索されたものなので、if条件でフィルタリングできます。
def parse(self, response):
df = pd.DataFrame()
xlink = LinkExtractor()
link_list=[]
link_text=[]
divs = response.xpath('//div')
text_list=[]
for span in divs.xpath('text()'):
if len(str(span.get()))>100:
text_list.append(span.get())
for link in xlink.extract_links(response):
if len(str(link))>200 or 'Journal'in link.text:
#print(len(str(link)),link.text,link,"
link_list.append(link)
link_text.append(link.text)
for i in range(len(link_text)-len(text_list)):
text_list.append(" ")
df['links']=link_list
df['link_text']=link_text
df['text_meta'] = text_list
df.to_csv('output.csv')
|
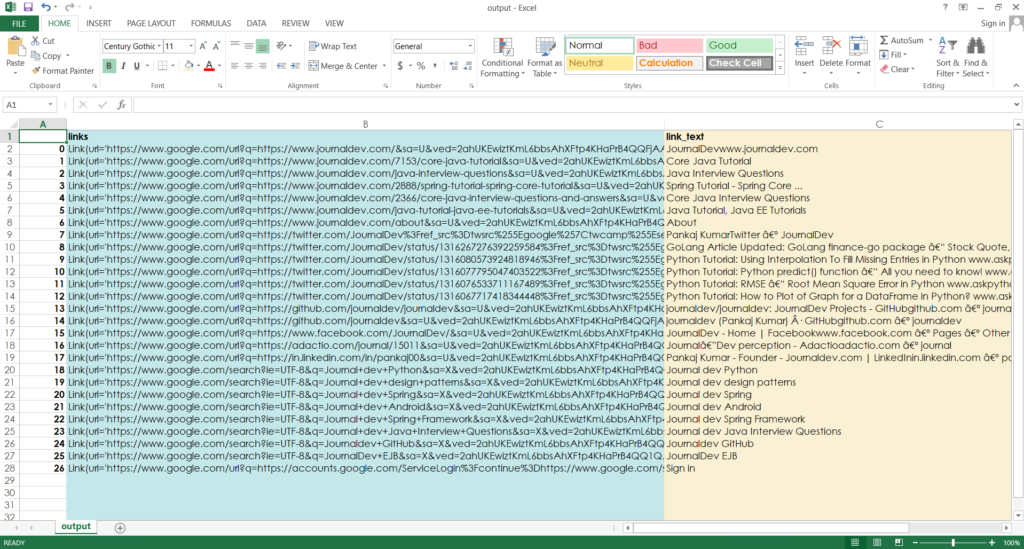
そして、出来上がり ここで再びスパイダーを走らせると、私たちのウェブサイトに関連するリンクだけが、テキストの説明文と一緒に取得されます。
ここで終了です。
DataFrameに入れる
しかし、ターミナルの出力はほとんど役に立ちません。
もし、これ以上のことをしたいのであれば(リストの各ウェブサイトをクロールするとか、誰かに渡すとか)、これをファイルに出力する必要があります。
このために、pandasを使います。

そして、これを実行すると、”output.csv “という出力ファイルが得られます。

メタデスクリプションを抽出する
さらに一歩進んで、テキストの下にある説明文にもアクセスすることができます。
そこで、parse関数を修正します。
response.xpath(//div/text()) を使って、div タグに存在するすべてのテキストを取得するのです。
そして単純な観察で、それぞれのテキストの長さをターミナルに出力してみると、100以上のものはdesciptionsである可能性が高いことがわかりました。
リンクと同じ順番で取得されるので、並べるのに問題はない。

このコードを実行すると、4番目のカラムが表示されます。

以上です。
もし、コードを見逃した場合は、ここですべてのコードを見ることができます: https://github.com/arkaprabha-majumdar/google-crawler
お読みいただきありがとうございました。
他の記事もチェックして、プログラミングを続けてください。
では、また。