
この記事は、PythonのPandasライブラリを使って、テキストファイルを読み込む方法についての簡単なチュートリアルです。テキストファイルは、現在では多くの生の情報を保存するのに役立っています。テキストファイルは、特定の情報にアクセスするための最も簡単な方法の1つです。テキストファイルには次のようなものがあります。
- コード
- 生情報
- リンク
- メッセージとその他多数
このような情報を管理するために、必要な情報を簡単に抽出するためのツールやテクニックがあります。そのひとつが、コンピュータ・プログラミングです。では、その方法をもう少し詳しく見てみましょう。
Python Pandasを使ったテキストファイルの読み方 ## Steps to Read Text Files using Python Pandas
コンピュータの中のファイルは、様々な数のファイルや拡張子を保存することができます。一般的に、ファイルとはあらゆるものの情報を保存するためのものです。だから、そのための特定の定義はありません。しかし、その拡張子はそれらについて多くを語っています。すべての拡張子は、その中に格納されているデータの異なるビットを定義しています。
例えば、pythonのような特定のプログラミング言語のファイルには、.pyという拡張子がついています。拡張子は、それがどのようなタイプのファイルであり、どのようなデータを表しているかを示すためのものです。
Windowsでsample.txtファイルを作成する
Windowsでテキストファイルを作成する方法は、とても簡単です。以下の手順で行ってください。
- Windowsの検索バーで「メモ帳」と入力します。それをクリックします。
- それは空白のページで開きます。そこに好きなテキストや情報を入れて、いつでも変更することができます。
- 3.作業が終わったら、Ctrl+Sを押すか、左上のファイルオプションに移動して、保存をクリックして、希望の場所にファイルを保存します。
Pandasでテキストファイルを読み込む
Pandasは、必要なデータの一部をカバーするPythonのライブラリです。主にデータサイエンスや機械学習の分野で使用されています。Pythonと同じくオープンソースのプロジェクトで、誰でも開発に貢献することができます。
詳しくはこちらをご覧ください。以下のような用途があります。
- データ解析
- データの前処理
- データクリーニング
- データラングリング
- 外部リンクに埋め込まれたファイルからの情報へのアクセス
- JSON, SQL, Excel ファイル形式からのデータ抽出。
Pythonと他のサポートライブラリで構成されており、大量のデータを管理するための最適なワークスペースを提供します。
Python Pandasのテキストファイルメソッド
データサイエンスでは、取得する情報量が膨大なので、すべてデータセットと呼ばれるファイルに格納されます。このデータセットは、様々な入力を持つ何千もの行と列になることがあります。Pandasはデータを処理するための関数やメソッドをたくさん提供しています。
read_excel() : エクセルファイルの読み込み
read_csv() : カンマ区切りファイルを読み込む。
info() : すべてのカラムの情報を表示する。
isna() : 値の欠損をチェックする。
5. sum() : 様々なデータ型の任意の列の値の合計
dropna() : ある列を削除する。
7. head() : データセットの最初の5行を返す。ただし、中括弧の中で指定した番号にしたがって返すこともできる。
以上が主な関数です。事前にライブラリについてもっと知りたい方は、こちらのリンクからスタートガイドをご覧ください。
Pandasのインストール
Python PIP コマンド、すなわち ‘package installer for python’ を使うと、どんなシステムにも簡単に Pandas をインストールすることができます。しかし、これにはいくつかの制限があります。まず、コマンドプロンプトから
python --version |
Python 3.6以降であることを確認してください。
conda install pandas |
次に、以下のようにpip install pandasと入力します。
import pandas |
Anacondaを使用したPandasのインストール
注:このためには、システムにAnacondaがインストールされている必要があります。
PandasはAnacondaにプリインストールされていますが、参考のため、condaプロンプトから新しいライブラリを追加する方法を知っておくことにします。
Anacondaのプロンプトを開き、次のコマンドを入力します。
import pandas as pd data = pd.read_excel('train.xlsx') data.head() |
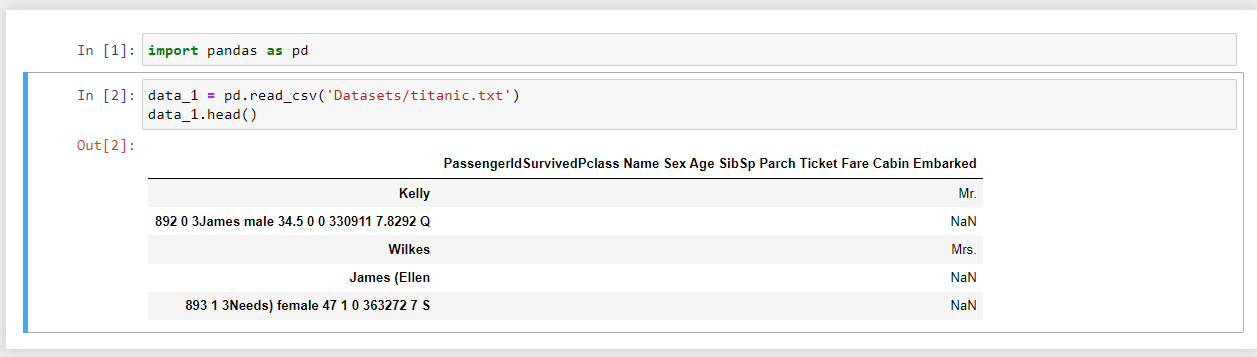
import pandas as pddata_1 = read_csv('titanic.txt')data_1.head() |
このように、このライブラリはすでにcondaの環境に存在していることが確認できました。
Pandasのインポート
さて、インストールして大まかな情報を得たら、次はもっと使いこなしていきましょう。まずはライブラリをインポートして、正しくインストールされているかどうかを確認します。
インストール後、エラーが出なければ使用可能です。
pandasでファイルを読み込む
チュートリアルは、ファイルを読むという非常にシンプルなものです。この中で、3種類のファイルを読みます。
- コマで区切られた値ファイル
- エクセルファイル
- テキストファイル
それぞれのファイルを読み込むための特別な関数があります。先ほど説明したように、read_excel()とread_csv()があります。 環境 – ‘Jupyter Notebooks’
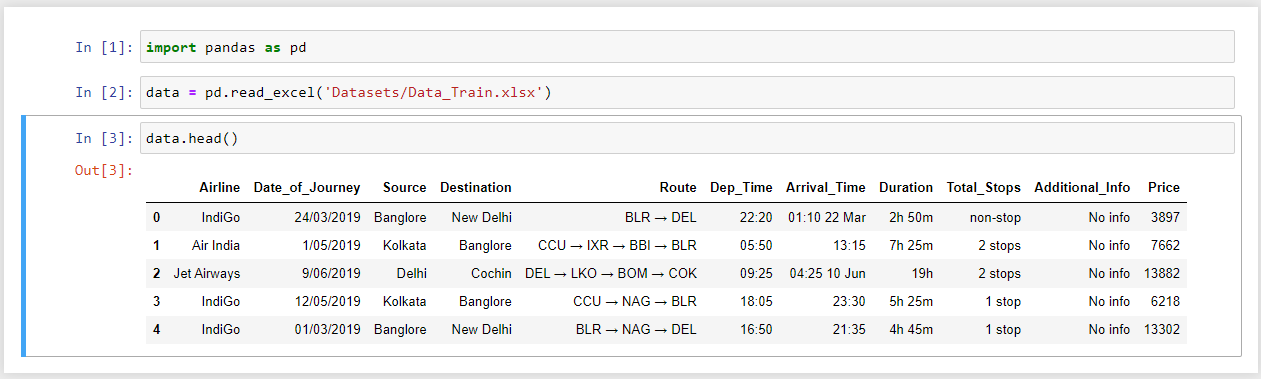
PythonでExcelファイルを読み込む。
使用したサンプルファイル – “train.xlsx”
結果は以下の通りです。
Pythonでテキストファイルを読み込む。
使用したサンプルファイル – “titanic.txt”
結果は以下の通りです。
結論
ここで、このトピックを終了します。このように、pandasを通していくつかのファイルを読み、データサイエンスと機械学習の旅をよりスムーズにすることができます。これが、pandasを使い始め、システムに設定するための最も適切な方法だと思います。
