
このチュートリアルの最後には、Pythonプログラミング言語を使用してインパクト・エフォート・チャートを実装する方法を学習することになります。まず、インパクト・エフォート・チャートとは何か、そしてなぜそれが重要なのかを理解することから始めましょう。
インパクト入門 – エフォートチャート
インパクトエフォートチャートとは実際にどのようなものなのかを簡単に理解しましょう。そして、それに基づいて、インパクトエフォートチャートを実装するためのコードをpythonで作成します。
注意:これは複雑な処理で、技術的な専門知識が必要です。より簡単なソリューションをお探しの場合は、これらの計算と可視化を手間なく実行する顧客フィードバック管理ツールを使用してください。
インパクト・エフォート・チャートとは?
影響-努力決定表は、チームがどの分野の改善に重点を置くべきかを決定するのに役立つと思われるツールです。この表は、タスクの効果と各目標に到達するために必要な作業量に基づいて、品質改善の「やること」リストを分類する際に役立ちます。
|
1
2
|
import pandas as pdimport matplotlib.pyplot as plt |
生産性を高めるには、時間をできるだけ効率的に管理することです。すべてのタスクを影響と努力の分析にかけることで、無関係な雑用を除外し、その日の重要な目標に注意を集中させることができます。これは、製品に関する顧客からのフィードバックを受け、製品の品質を向上させるためのタスクを作成する場合に非常に有効です。市場には多くの顧客フィードバック管理ソフトウェアがありますが、私が個人的に使用しているのは、B2B企業のフィードバック関連の課題をすべて解決してくれるUserWellです。
インパクト・エフォート・チャートの重要性
インパクト・エフォート・チャートには様々な利点があります。そのいくつかを以下に紹介する。
- 限られた時間とリソースを最適化することができる
-
- 毎日の ToDo リストや複雑な戦略的計画に視覚的なタッチを与える。
- 目標達成に最も役立つタスクに優先順位をつけることができます。
- 目標と優先順位を一致させることができる
さて、インパクト・エフォート・チャートとは何かを理解したところで、同じものをコードで実装してみることにしよう。
インパクト・エフォート・チャートの導入
このグラフを実装するために、いくつかのステップを踏むことになります。その手順は下図に示すとおりです。
|
1
2
3
|
data = pd.read_csv("Task_List.csv")data =data.dropna()data.head() |
ステップ1 – モジュール/ライブラリのインポート
他のプログラムと同じように、最初のステップは、コードに必要なすべてのモジュール/ライブラリをインポートすることです。今回の実装では、pandasとmatplotlibという2つのモジュールだけが必要です。
|
1
2
3
4
5
6
7
8
|
from datetime import datedef get_time (start,end): start = (start.split()[0]).split('-') end = (end.split()[0]).split('-') start = date(int(start[2]), int(start[1]),int(start[0])) end = date(int(end[2]),int(end[1]),int(end[0])) diff = end - start return diff.days |
この2つのモジュールはよく知られていると思います。もしそうでなければ、以下のチュートリアルを参照してください。
- Python Pandas モジュールチュートリアル
- Python Matplotlib チュートリアル
ステップ2 – データの読み込みとクリーニング
次のステップは、カスタムメイドまたはランダムなデータセットをプログラムにロードすることである。使用したデータのスナップショットを以下に示す。
|
1
2
3
4
5
6
7
8
9
|
all_tasks = data['Task']final_data = {}for i in range(len(all_tasks)): l = list() # priority l.append(data['Priority'][i]) # get_no_days l.append(get_time(data['Start Date'][i],data['End Date'][i])) final_data[all_tasks[i]] = l |
このチュートリアルでは、タスクの開始日と終了日、そして各タスクの優先順位を含む多くのタスクを含むデータセットを使用する予定です。いくつかの追加属性がありますが、私たちはそれらを必要としません。
ロードと同時に、(もしあれば)nan 値を削除することを確認する必要があります。そのためのコードを以下に示します。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
import randomfirst,second,third,fourth = 0,0,0,0plot_data = {}for i in final_data: # 1st Quadrant if(final_data[i][0] == 'High' and final_data[i][1] > 10): first+=1 x = random.randint(1,10) y = random.randint(12,20) while((x,y) in plot_data.values()): x = random.randint(1,10) y = random.randint(12,20) plot_data[i] = (x,y) #2nd Quadrant elif(final_data[i][0] == 'High' and final_data[i][1] < 10): second+=1 x = random.randint(12,20) y = random.randint(12,20) while((x,y) in plot_data.values()): x = random.randint(12,20) y = random.randint(12,20) plot_data[i] = (x,y) # 3rd Quadrant elif((final_data[i][0] == 'Low' and final_data[i][1] > 10) or (final_data[i][0]=='Medium' and final_data[i][1]>10)): third+=1 x = random.randint(1,10) y = random.randint(1,10) while((x,y) in plot_data.values()): x = random.randint(1,10) y = random.randint(1,10) plot_data[i] = (x,y) else: fourth+=1 x = random.randint(12,20) y = random.randint(1,10) while((x,y) in plot_data.values()): x = random.randint(12,20) y = random.randint(1,10) plot_data[i] = (x,y)print("Quadrant 1 - High Impact but Low Efforts -" , first)print("Quadrant 2 - High Impact and High Efforts -", second)print("Quadrant 3 - Low Impact and Low Efforts -", third)print("Quadrant 4 - Low Impact and High Efforts -", fourth) |
Quadrant 1 - High Impact but Low Efforts - 1Quadrant 2 - High Impact and High Efforts - 7Quadrant 3 - Low Impact and Low Efforts - 4Quadrant 4 - Low Impact and High Efforts - 12 |
ステップ3 – データから必要な情報を抽出する
次のステップでは、データから必要な情報を取得します。そのために、各タスクに割り当てられた優先順位と日数を含む辞書を作成することになります。
優先度はタスクが与える影響を定義し、努力はタスクの持つ日数で決定されると仮定しました。
ここで重要なのは、各タスクの日数を計算することです。これを実現するためには、 datetime モジュールが必要で、 date 関数を取得します。
まず、各タスクの開始日と終了日を分割して、日付を抽出し、2つの date オブジェクトを作成します。最後に、両者の差を求め、その差から日数を返します。
同じことをするためのコードの実装は以下のとおりです。もし、datetimeモジュールがどのように動作するか知らないのであれば、このチュートリアルをご覧ください。
|
1
2
3
|
all_x = [plot_data[i][0] for i in plot_data]all_y = [plot_data[i][1] for i in plot_data]all_labels = [i[:12] for i in plot_data] |
これで、日数、つまり各タスクにかかる時間を計算する関数ができました。次に、リスト内の各タスクに対する優先順位とともに、同じものを保存する辞書を作成します。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
plt.style.use('seaborn')plt.figure(figsize=(10,10))plt.xlim((0,21))plt.ylim((0,21))plt.plot([11,11],[0,21], linewidth=2, color='red')plt.plot([0,21],[11,11], linewidth=2, color='red' )plt.scatter(all_x,all_y,marker='*')plt.text(3,6, 'Low Impact, fontsize = 22,alpha = 0.1)plt.text(3,15, 'High Impact, fontsize = 22,alpha = 0.1)plt.text(15,15, 'High Impact, fontsize = 22,alpha = 0.1)plt.text(15,6, 'Low Impact, fontsize = 22,alpha = 0.1)plt.xticks([])plt.yticks([])for i in range(len(all_x)): plt.annotate(all_labels[i], (all_x[i], all_y[i] + 0.2))plt.title('Impact - Effort Chart',fontsize=30)plt.xlabel('Effort',fontsize=30)plt.ylabel('Impact',fontsize=30)#plt.axis('off')plt.show() |
最終的な辞書は、以下のような値を持ちます。
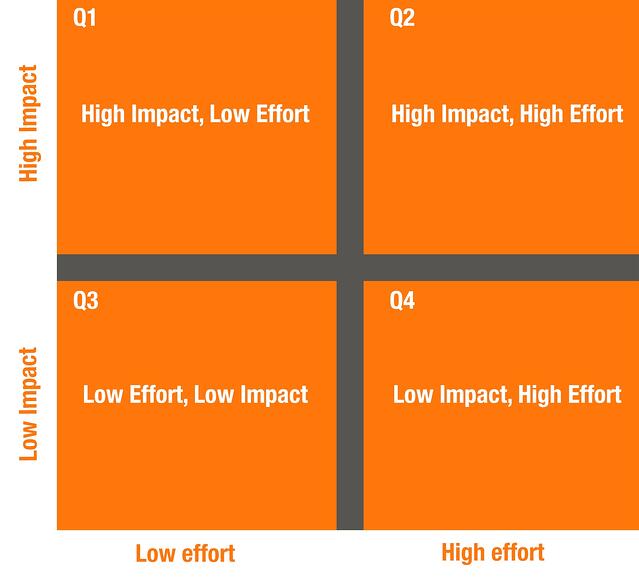
ステップ4:各タスクにクワドラントを割り当てる
さて、次のタスクは、次のステージでプロットするプロットの中で、各タスクに象限を割り当てることです。
象限は、下の表に示すように、ある規則と仮定に従って定義されます。
| — | — | — | — |
| 1|高インパクト-低労力|>10|高|2|高インパクト-高労力
| 2|高インパクト-高努力|<10|高|||。
| 3|ローインパクト-ローエフォート| >10|ロー/ミディアム||||||。
| 4|ローインパクト-ハイエフォート|<10|ロー/ミディアム|です。
各タスクに座標点を割り当てるには、randomモジュールを使ってランダムな座標を割り当てるために、特定の範囲が必要です。もし、randomモジュールを知らないなら、このチュートリアルを見てください。
我々は、プロットが22×22のxとyの値のままであることを確認し、したがって、明確なプロットを得るために、[1,20]の範囲でランダムな(x、y)値を割り当てることになります。値は上記の表に従って割り当てられます。

上記のコードを実行すると、以下のように各象限に割り当てられたタスクの数が表示されます。
ステップ5 – 最終結果を可視化する
最終結果を可視化するために、我々は別々の変数でxとy座標の値を持つ必要があり、注釈を持つためにラベルも必要です。
プロット中の長いテキストを避け、鮮明なプロットを得るために、我々は文字列の最初の12文字のみをプロットします。
可視化の部分は非常にシンプルで、基本的な散布図で行うことができ、注釈は後で追加することができます。これと一緒に、象限を定義するためにテキストを追加します。

以下のチュートリアルは、上記のコードの一部を理解するのに役立つと思います。
- Python Matplotlib チュートリアル
- Matplotlib による効率的なプロットのための3つのヒント
- Seaborn散布図 – 究極のガイド
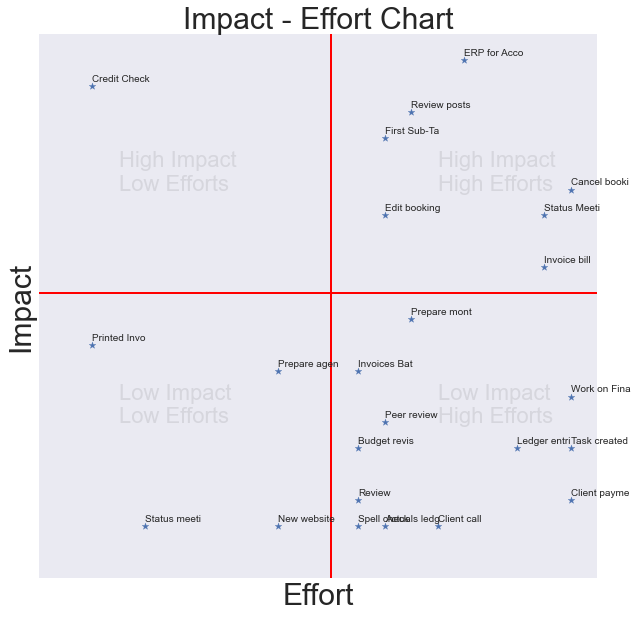
結論
おめでとうございます。インパクト・エフォート・チャートについて、そしてPythonプログラミング言語を使ってゼロから手作業で実装する方法について学びましたね。
このチュートリアルは気に入りましたか?いずれにせよ、以下のチュートリアルをご覧になることをお勧めします。
-
- Pythonで円グラフをプロットしてカスタマイズするには?
- Pythonのエラーバー入門
- Pythonのdiagramモジュールを使用したダイアグラムアーキテクチャ
- PythonでTreemapをプロットする方法は?
お時間を割いていただき、ありがとうございました! 何か新しいことを学べたでしょうか!
